Recently I was coaching a python programmer by way of text conversation on Discord. It was after a long day at work, my hands were feeling fatigued, and I thought to myself
[I work from home, therefore] I already have a microphone in front of my face, and LLMs exist. I bet STT to the clipboard would be pretty easy…
If I’ve ever heard famous last words, those are them, but it actually did turn out to be relatively easy.

The goal is not just to transcribe audio, but to have a script that will listen to me speak, transcribe the audio to text, and put that text into my system clipboard so I can easily paste it into an email, Slack message, etc…, with a single command.
Speech-to-Text Transcription
First, I wanted to make sure the transcription step was actually as easy as I was assuming. A search for STT APIs brought me to Deepgram Voice Ai, who offer a generous $200 credit to a new account. We’re good to go there, but we aren’t going to hit the API until we have some audio to transcribe…
Recording My Voice (from the Command Line)
As I was making the mistake of searching for Python libraries to record audio, it occurred to me that I already knew my system audio was being managed by Pulse and, for some unrelated reason lost to time, I had recently learned that I could play an audio file with the pacat command. There is probably a simple command for recording already available in the terminal. Let’s check out the man page for pacat:

Bingo - pacat also includes parecord, an alias for using the -r flag. A quick experiment showed no options were required to record from my default audio device:
parecord test.mp3 # record
pacat text.mp3 # playbackThe parecord command will run, continuing to record audio, until you interrupt it (with a Ctrl+C in this case). The audio is then rendered to the filepath provided (test.mp3).
Since API calls can be done with curl or wget, this means we can do the entire workflow in bash!
A Small Problem
Listening back to the test file with pacat, only the audio which had been fully rendered at the time of the interrupt was retained, leaving off a few seconds at the end of the recording (a few words, unless you pause long enough before interrupting the command).
Ideally, the user should be able to signal to the program that they are done recording at any point after they finish talking. I am not a professional bash developer, and this problem took the majority of this project’s time. I ultimately ended up with this, and would love to know if there is a better way (aside from not using bash):
# run the recording in a separate process
parecord 'test.mp3' &
# get the process ID of the previous command
parec_pid=$!
while : # infinite loop
do
# read keyboard input
read -n 1 key
# if a q is seen...
if [ "$key" = "q" ]; then
# wait 2 seconds for the recording to render
sleep 2s
# kill the recording process
kill -SIGINT $parec_pid
# break the infinite while loop
break
fi
doneBetter File Name Handling
We need to get rid of the hardcoded test.mp3 file name and either:
- Let the user specify the filename OR
- Name the file automatically with a smarter naming convention.
# make a directory in /tmp/ for holding our recordings
mkdir -p /tmp/dictation
# if the user has provided an argument (filename)...
if [ $# -gt 0 ]; then
# replace spaces with underscores and use input as filename
filename=$(echo $@ | sed 's/ /_/g')
else
# otherwise, use a timestamp as the filename
# with seconds included to avoid duplicate filenames
filename=$(date +%s)
fi
# set the final file location in our /tmp/dictation directory from earlier
file_loc="/tmp/dictation/$filename.mp3"The Recording Script
Putting these together gives us a complete recording script (below). I’ve added some echo outputs for the user:

#!/usr/bin/env bash
mkdir -p /tmp/dictation
# check for filename or use timestamp
if [ $# -gt 0 ]; then
filename=$(echo $@ | sed 's/ /_/g')
else
filename=$(date +%s)
fi
file_loc="/tmp/dictation/$filename.mp3"
parecord $file_loc &
parec_pid=$!
echo "recording. press q to stop"
# loop waits for 'q' and stops recording
while :
do
read -n 1 key
if [ "$key" = "q" ]; then
echo && echo "stopping recording..."
sleep 2s
kill -SIGINT $parec_pid
break
fi
done
echo "${file_loc} saved."Deepgram
We’re saving audio successfully, so now it’s time to send it off to the Deepgram API for transcription. The documentation has examples for remote files and for local files - we want the local file example:
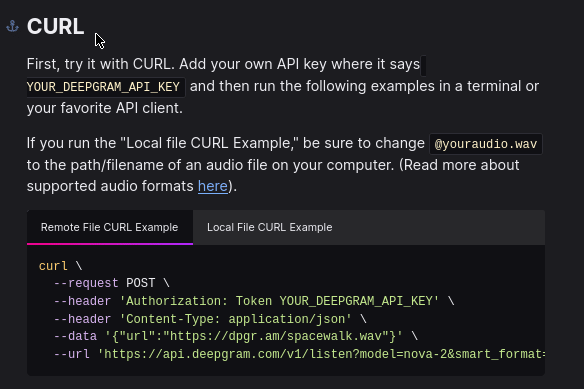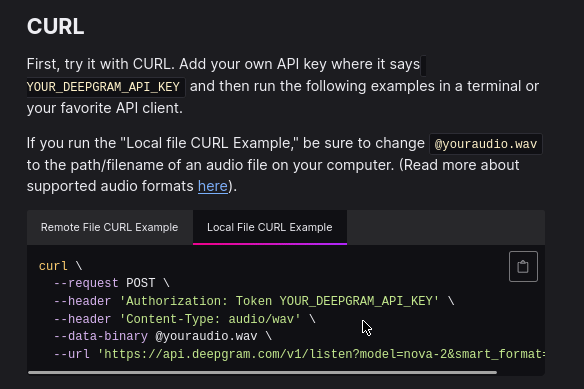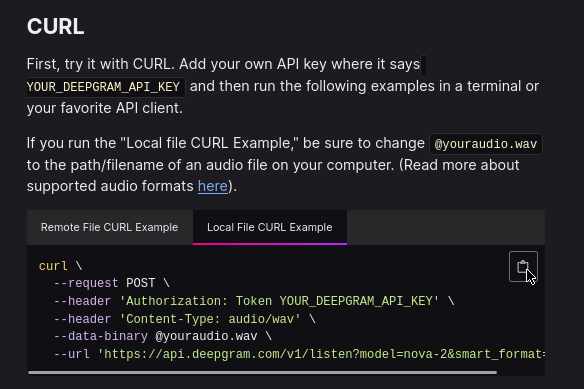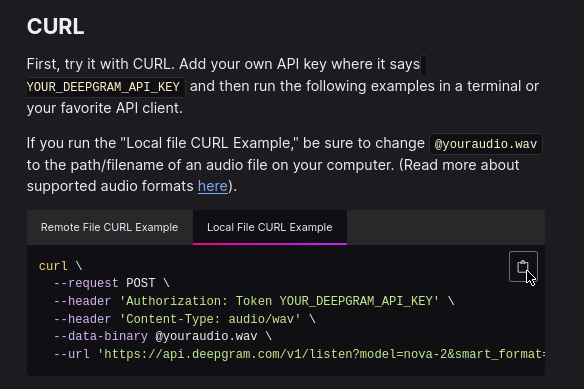
Editing the Request
curl \
--request POST \
--header 'Authorization: Token YOUR_DEEPGRAM_API_KEY' \
--header 'Content-Type: audio/wav' \
--data-binary @youraudio.wav \
--url 'https://api.deepgram.com/v1/listen?model=nova-2&smart_format=true'We’re going to use the default model and format rules from this example, so the two variables we need to concern ourselves with are the audio we want to transcribe and our Deepgram API key. Our recording script from above is already providing us with the audio file, so we’ll get to that later.
API Key
Rather than set my API key as an environment variable, I have saved it at a local location in my home directory, from which the script will read before providing the token to the request.
DEEPGRAM_API_KEY="$(head -1 "$HOME/path/to/my/deepgram/token")"
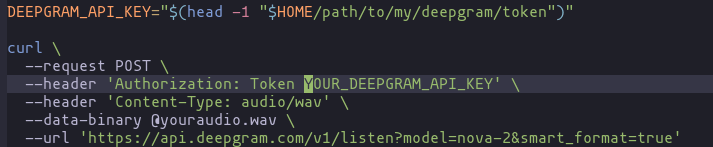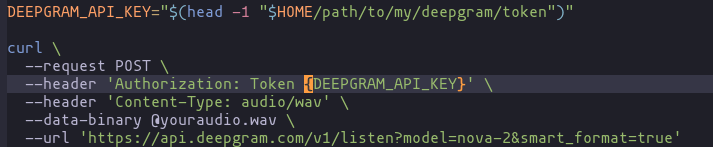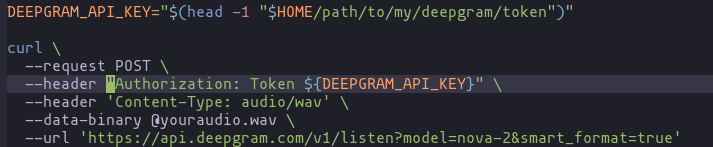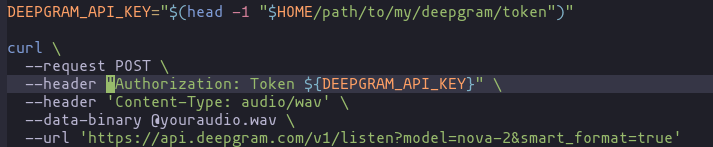
curl \
--request POST \
--header "Authorization: Token ${DEEPGRAM_API_KEY}" \
--header 'Content-Type: audio/wav' \
--data-binary @youraudio.wav \
--url 'https://api.deepgram.com/v1/listen?model=nova-2&smart_format=true'Specifically note the change from the example’s single quotes to a set of double quotes when inserting the variable:
This is Only a Test
Running a test with our test recording from earlier…
--data-binary @/tmp/dictation/test.mp3 \And it works! But it doesn’t just return the simple text we’re looking for, the response we get back is JSON.
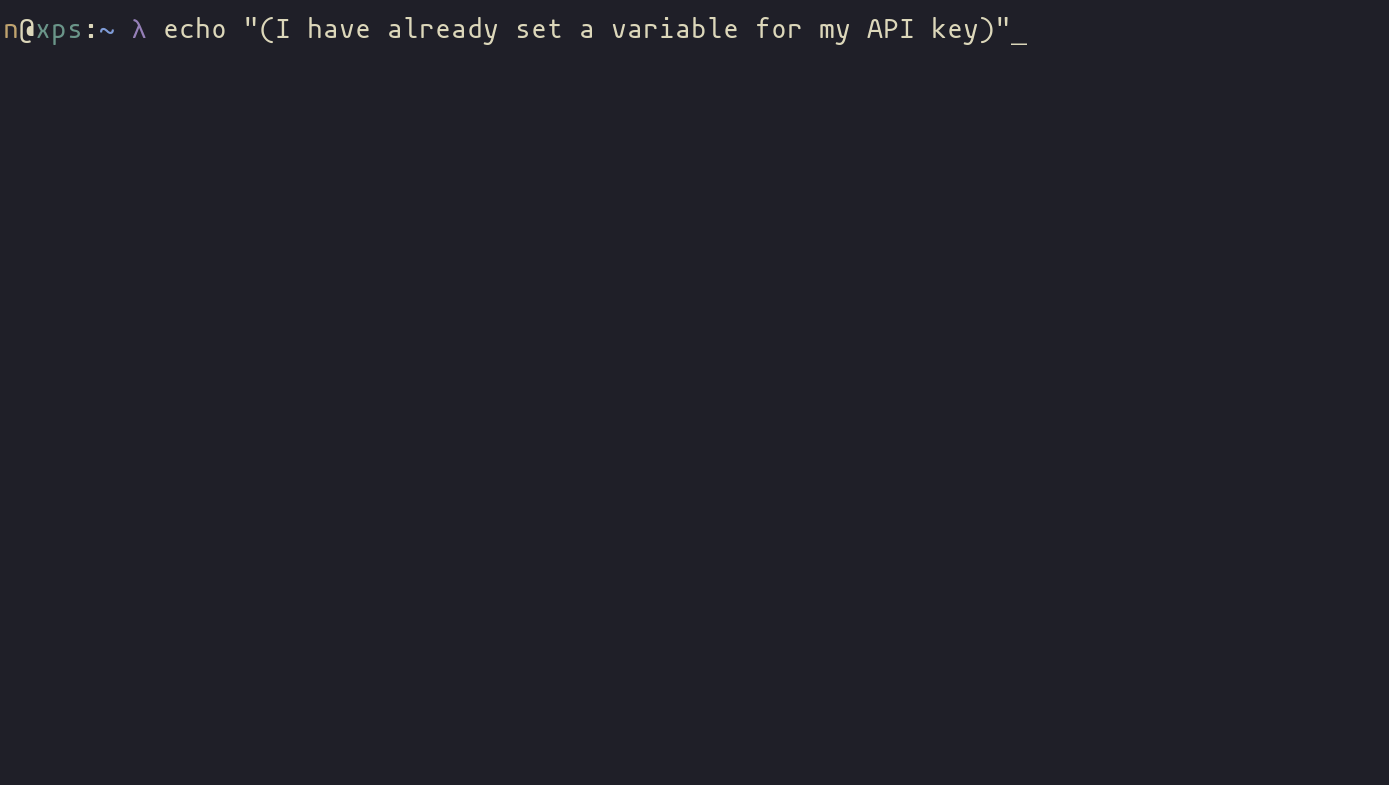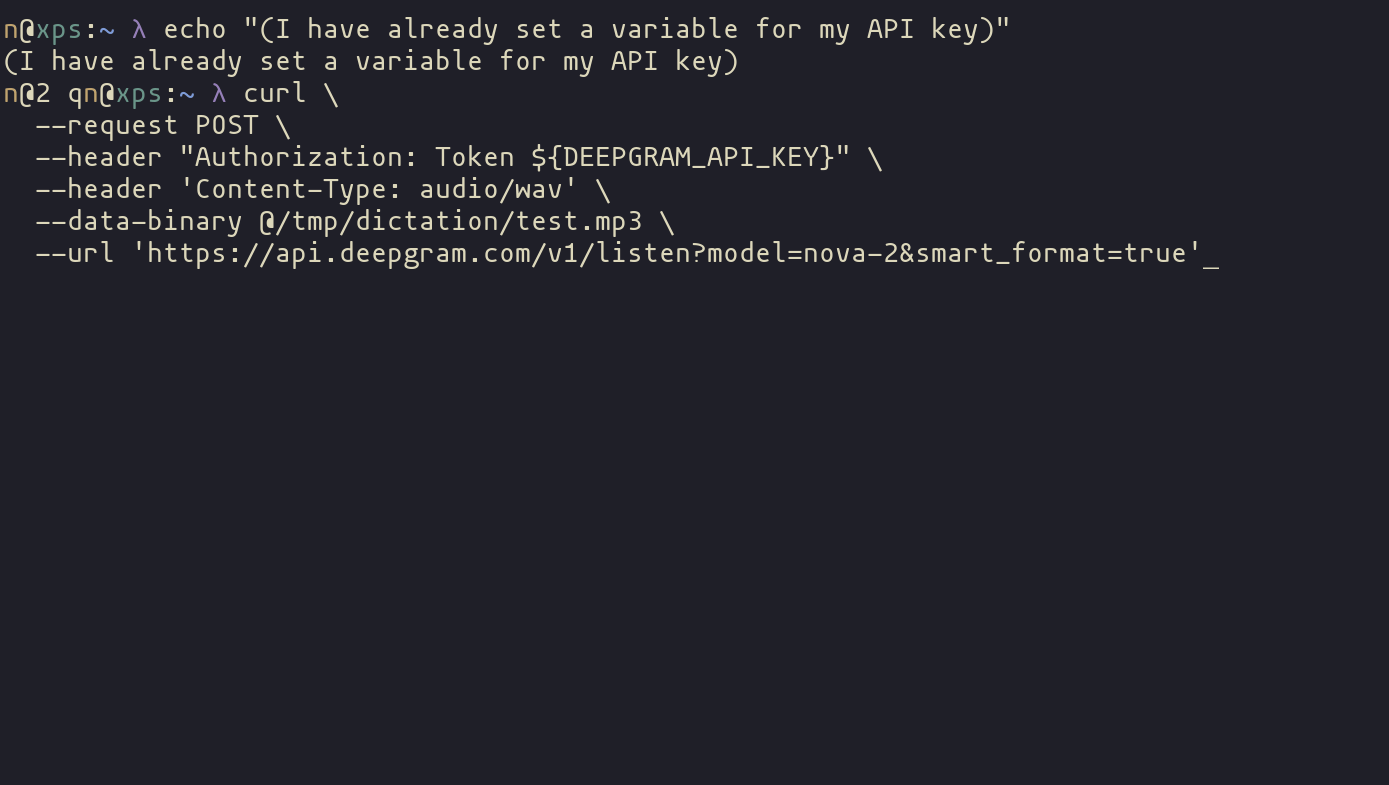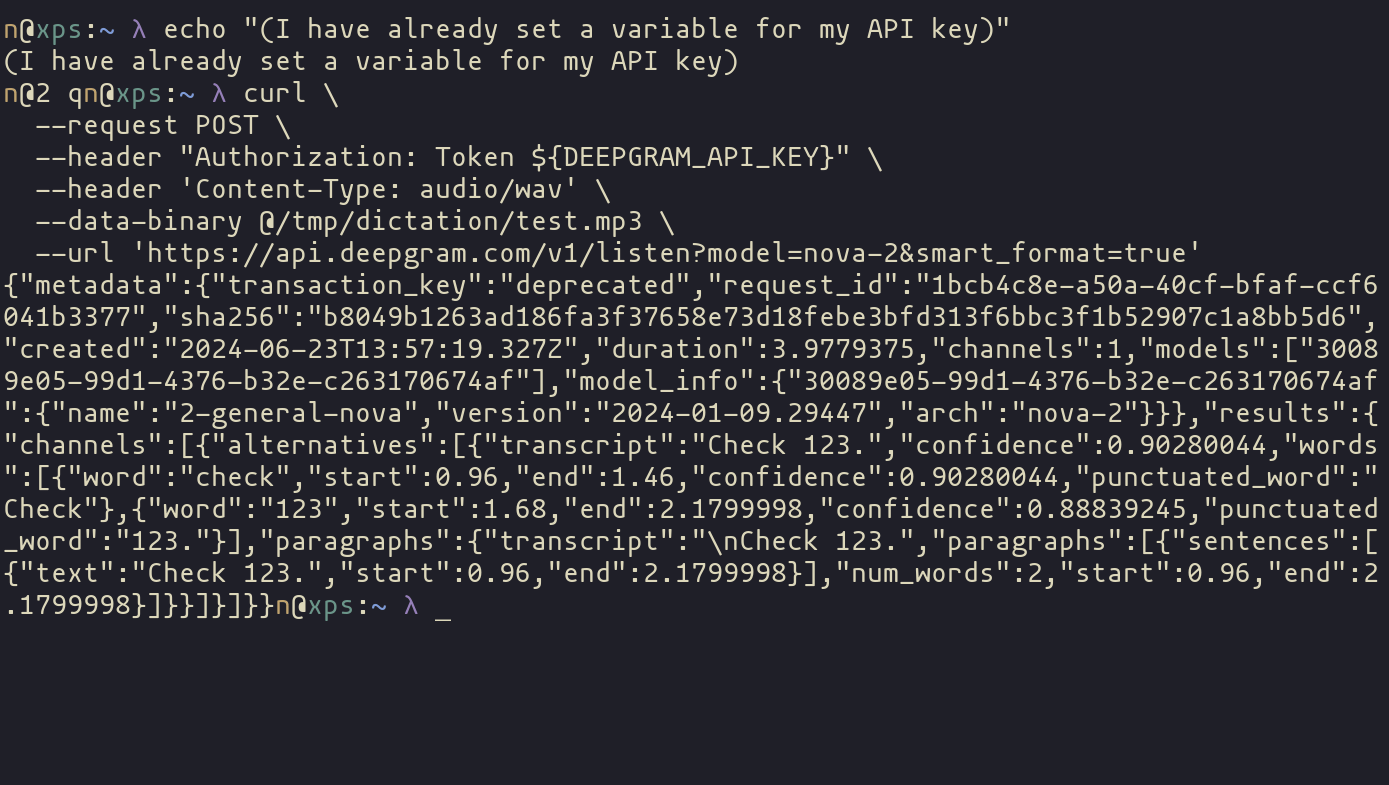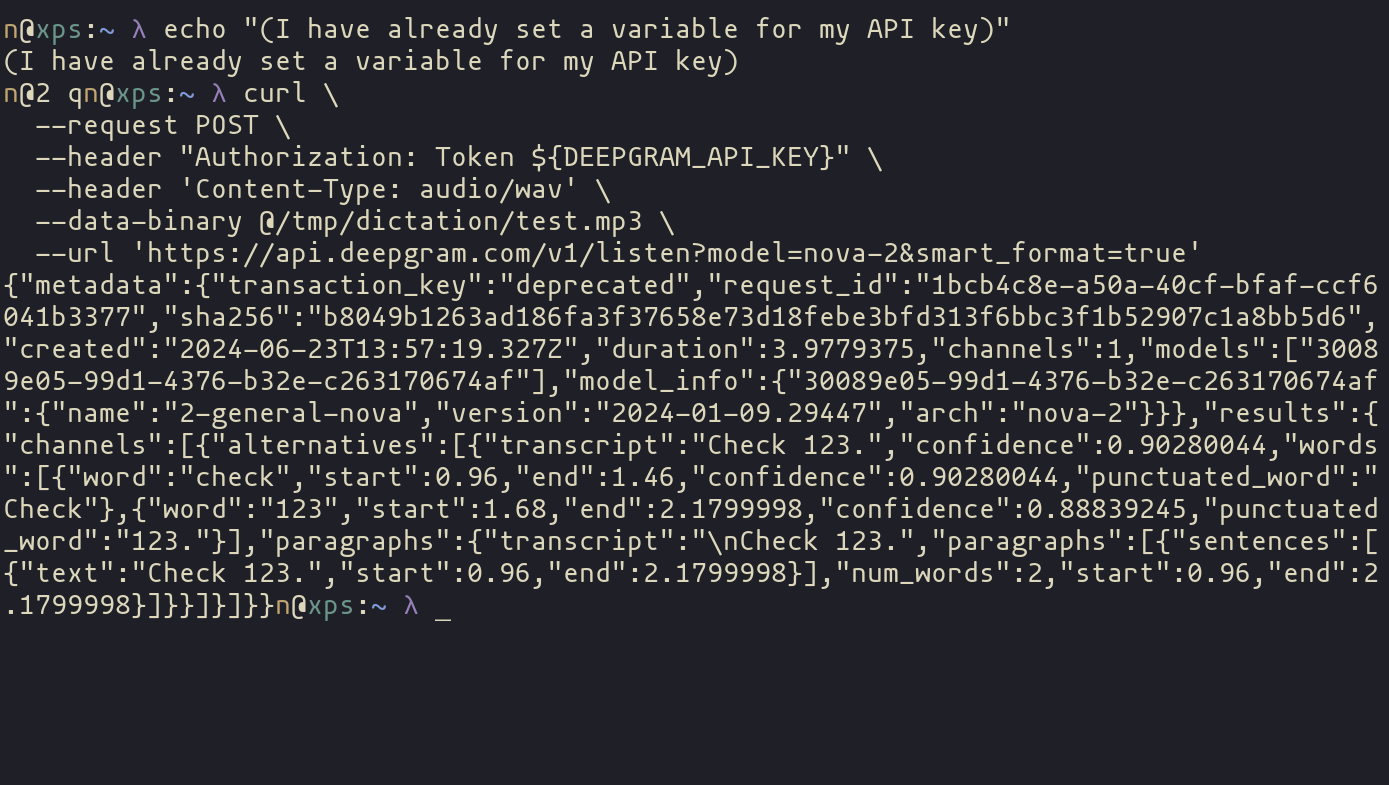
Parsing the Response
Let’s add an output flag to the transcription call to save the file so we can work with it without re-calling the API again and again:
curl -o /tmp/dictation/test.json \
# ...jq
Next we’ll use jq to make the output more readable:
cat /tmp/dictation/test.json | jq{
"metadata": {
"transaction_key": "deprecated",
"request_id": "73edfe3e-404b-4331-8736-1629c9b101f6",
"sha256": "redacted because it's probably sensitive",
"created": "2024-06-23T13:58:29.948Z",
"duration": 3.9779375,
"channels": 1,
"models": [
"30089e05-99d1-4376-b32e-c263170674af"
],
"model_info": {
"30089e05-99d1-4376-b32e-c263170674af": {
"name": "2-general-nova",
"version": "2024-01-09.29447",
"arch": "nova-2"
}
}
},
"results": {
"channels": [
{
"alternatives": [
{
"transcript": "Check 123.",
"confidence": 0.90280044,
"words": [
{
"word": "check",
"start": 0.96,
"end": 1.46,
"confidence": 0.90280044,
"punctuated_word": "Check"
},
{
"word": "123",
"start": 1.68,
"end": 2.1799998,
"confidence": 0.88839245,
"punctuated_word": "123."
}
],
"paragraphs": {
"transcript": "\nCheck 123.",
"paragraphs": [
{
"sentences": [
{
"text": "Check 123.",
"start": 0.96,
"end": 2.1799998
}
],
"num_words": 2,
"start": 0.96,
"end": 2.1799998
}
]
}
}
]
}
]
}
}Much better!
This data is small enough for us to read and determine that our target is in results > channels > alternatives > transcript but if your data is too unwieldy to scroll through, we can use jq to get the keys of the outermost mapping:
cat /tmp/dictation/test.json | jq "keys"[
"metadata",
"results"
]Then we can use those keys to index the nested structure:
cat /tmp/dictation/test.json | jq ".results"{
"results": {
"channels": [
{
"alternatives": [
{
"transcript": "Check 123.",
"confidence": 0.90280044,
"words": [
{
"word": "check",
"start": 0.96,
"end": 1.46,
"confidence": 0.90280044,
"punctuated_word": "Check"
},
{
"word": "123",
"start": 1.68,
"end": 2.1799998,
"confidence": 0.88839245,
"punctuated_word": "123."
}
],
"paragraphs": {
"transcript": "\nCheck 123.",
"paragraphs": [
{
"sentences": [
{
"text": "Check 123.",
"start": 0.96,
"end": 2.1799998
}
],
"num_words": 2,
"start": 0.96,
"end": 2.1799998
}
]
}
}
]
}
]
}
}Check the keys of the result, then query further:
cat /tmp/dictation/test.json | jq ".results | keys"[
"channels"
]cat /tmp/dictation/test.json | jq ".results.channels"[
{
"alternatives": [
{
"transcript": "Check 123.",
"confidence": 0.90280044,
"words": [
{
"word": "check",
"start": 0.96,
"end": 1.46,
"confidence": 0.90280044,
"punctuated_word": "Check"
},
{
"word": "123",
"start": 1.68,
"end": 2.1799998,
"confidence": 0.88839245,
"punctuated_word": "123."
}
],
"paragraphs": {
"transcript": "\nCheck 123.",
"paragraphs": [
{
"sentences": [
{
"text": "Check 123.",
"start": 0.96,
"end": 2.1799998
}
],
"num_words": 2,
"start": 0.96,
"end": 2.1799998
}
]
}
}
]
}
]channels is a list, so we access it with a pair of square brackets. The same is true for its child alternatives:
cat /tmp/dictation/test.json | jq ".results.channels[].alternatives[]"[
{
"transcript": "Check 123.",
"confidence": 0.90280044,
"words": [
{
"word": "check",
"start": 0.96,
"end": 1.46,
"confidence": 0.90280044,
"punctuated_word": "Check"
},
{
"word": "123",
"start": 1.68,
"end": 2.1799998,
"confidence": 0.88839245,
"punctuated_word": "123."
}
],
"paragraphs": {
"transcript": "\nCheck 123.",
"paragraphs": [
{
"sentences": [
{
"text": "Check 123.",
"start": 0.96,
"end": 2.1799998
}
],
"num_words": 2,
"start": 0.96,
"end": 2.1799998
}
]
}
}
]cat /tmp/dictation/test.json | jq ".results.channels[].alternatives[] | keys"[
"confidence",
"paragraphs",
"transcript",
"words"
]An item in alternatives contains the full transcript that we are looking for, a confidence score (from 0 to 1), and a by-paragraph and by-word breakdown. Let’s get the transcript:
cat /tmp/dictation/test.json | jq ".results.channels[].alternatives[].transcript""Check 123."“Removing the Quotes”
The output from jq includes a set of quotes that we don’t want in our final product; we can remove them with sed, which can use pattern matching for text replacement:
cat /tmp/dictation/test.json \
| jq ".results.channels[].alternatives[].transcript" \
| sed 's/^"\(.*\)"$/\1/'Check 123.Looking good!
Copying the Transcription to the Clipboard
The bow on top of this project is copying the resulting transcription to the clipboard for easy pasting into your AIM conversation or MySpace post. For this we’ll use xclip:
WHAT IS XCLIP?
==============
xclip is a command line utility that is designed to run on any system with an
X11 implementation. It provides an interface to X selections ("the clipboard")
from the command line. It can read data from standard in or a file and place it
in an X selection for pasting into other X applications. xclip can also print
an X selection to standard out, which can then be redirected to a file or
another program.Usage is pretty straightforward; we use the -i flag to push text into the clipboard (alternatively, the -o flag can be used to read the contents of the clipboard):
echo "Hi mom!" | xclip -i -selection clipboardHere’s what it would look like added to our parsing test code:
cat /tmp/dictation/test.json \
| jq ".results.channels[].alternatives[].transcript" \
| sed 's/^"\(.*\)"$/\1/'
| xclip -i -selection clipboardPutting It All Together
The final script is below, see the [NOTE]s for explanation of things not explicitly shown above. Here it is in action:

#!/usr/bin/env bash
DEEPGRAM_API_KEY="$(head -1 "$HOME/path/to/my/deepgram/token")"
mkdir -p /tmp/dictation
# check for filename or use timestamp
if [ $# -gt 0 ]; then
filename=$(echo $@ | sed 's/ /_/g')
else
filename=$(date +%s)
fi
file_loc="/tmp/dictation/$filename.mp3"
parecord $file_loc &
parec_pid=$!
echo "recording. press q to stop"
# loop waits for 'q' and stops recording
while :
do
read -n 1 key
if [ "$key" = "q" ]; then
echo && echo "stopping recording..."
sleep 2s
kill -SIGINT $parec_pid
break
fi
done
echo "${file_loc} saved."
# [NOTE]: set the output location for Deepgram's response data using file_loc from the record phase
output_loc=$(echo $file_loc | sed 's/mp3/json/')
echo 'analyzing audio...'
curl -so $output_loc \
--request POST \
--header "Authorization: Token ${DEEPGRAM_API_KEY}" \
--header 'Content-Type: audio/wav' \
--data-binary @$file_loc \
--url 'https://api.deepgram.com/v1/listen?model=nova-2&smart_format=true'
echo "${output_loc} saved."
# [NOTE]: assign the transcript to a variable including quotes
transcript=$(cat $output_loc \
| jq ".results.channels[].alternatives[].transcript")
# [NOTE]: strip quotes before copying to clipboard
echo $transcript | sed 's/^"\(.*\)"$/\1/' | xclip -i -selection clipboard
echo $transcript
echo 'copied to clipboard'
This page lovingly generated by Quarto ❤️